content architecture
deep | dive
Jan. 2025 - Apr. 2025

Course
Professor
Design Degree
Eric Beacom
Strategy • Information Architecture • Content Modeling • Experience Design • Wireframes
•
Strategy • Information Architecture • Content Modeling • Experience Design • Wireframes •
Deep|Dive is a research‑first content system that turns fragmented music knowledge across the internet into navigable stories. It curates media around artists and scenes – timelines, genealogies, and explainable recommendations – so deep fans can explore without tab‑hopping. Personalization is framed through streaming‑platform APIs and a Pinterest‑like collections model, where what you play and what you save informs what surfaces. Within the scope of a semester, I defined the information architecture, taxonomy, page frameworks, and recommendation principles structured around coherence and clarity at the core. The result is a scalable approach that privileges linearity and context over algorithmic noise.
synopsis

Streaming solved listening access but not understanding. Superfans hop between Wikipedia, YouTube, Reddit, cultural magazines, and blogs in order to seek further connection with their favorite artists and genres – inefficient and high effort. As quantity and output continue to multiply, personalization and curation become principal for serious fans. There is a parallel resurgence of archival curiosity in documentaries, long-form interviews, artist brands and scene histories that signal demand for depth over feed. I created Deep|Dive as a platform that unifies media, clarifies relationships, and makes personalization legible – channeling interest and curiosity into a continuous path, away from the incongruous tab maze.
Basis and Positioning
1
The Deliverables
final wireframes
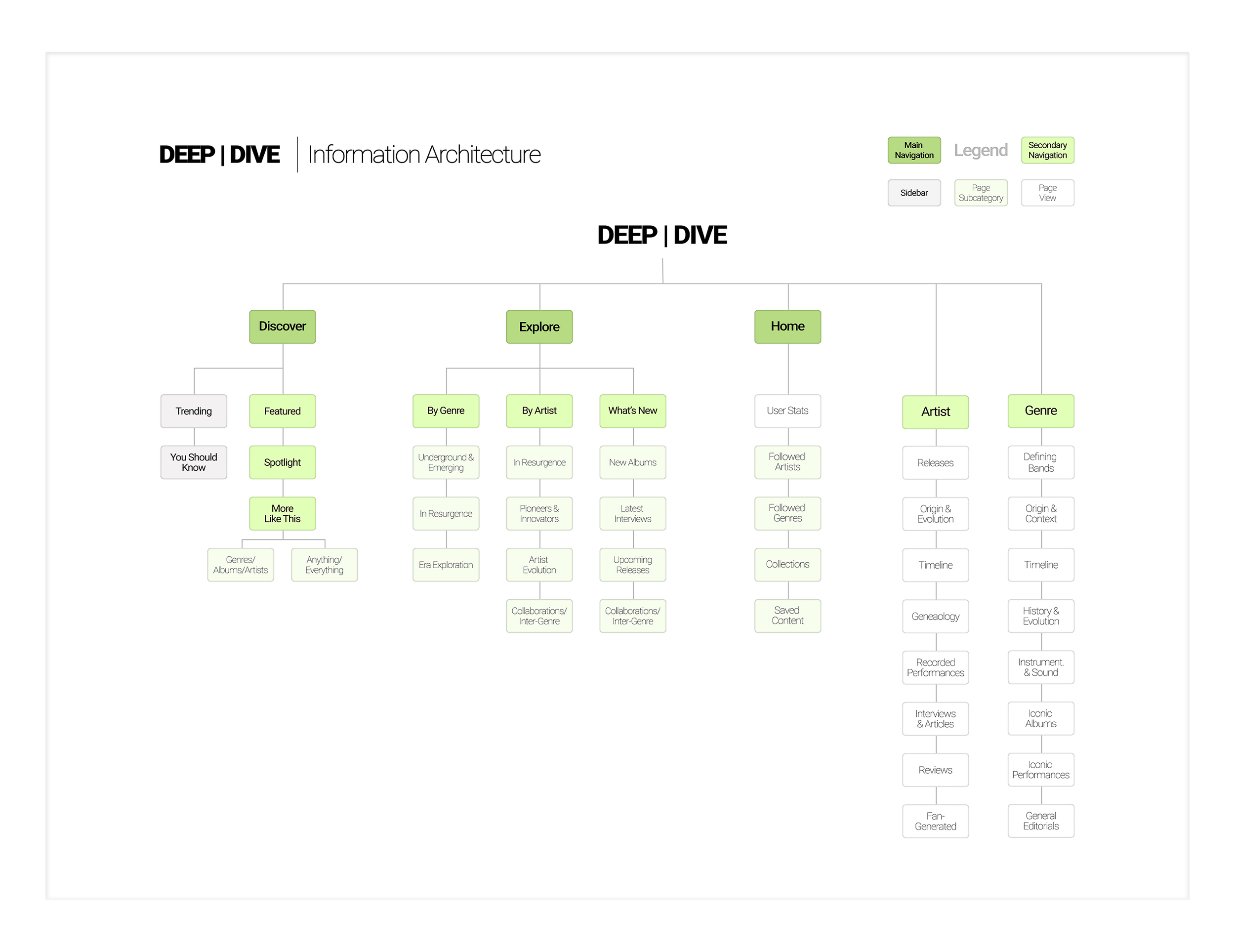
The sum of my efforts culminated in five wireframe pages, built on the information architecture, content frameworks, and artist/genre page applications I developed. Discover, Explore, and Home serve as the main navigation, while Artist (Slowdive) and Genre (Shoegaze) function as secondary pages.

information breakdown

Unify scattered and uneven media formats into a coherent information architecture that facilitates seamless exploration and discovery. Obstacles include:
Uneven data quality and gaps across artists/genres
Rights/provenance considerations (what to surface and how to attribute)
Avoiding over‑templating that erases nuance (particularly for underground artists)
Personalization without filter bubbles; ensure editorial balance
Designing a structure that scales across varied archives
The Challenge
information architecture (IA)
The information architecture defines the system’s hierarchy, content groupings, and decision paths – visualizing what lives where and how users move between related contexts. It resolves entry points, cross-links, and priority actions so the wireframes could focus on screen-level execution rather than structural questions.
content frameworks

This schema standardizes content across mediums – text (editorials, timelines, annotations), visuals (photography, branding, infographics), video (performances, documentaries, music videos), and audio (streams, interviews, exclusives) – and details field-level breakdowns for both Genre and Artist (history, identity/technique, notable works, aesthetics/brand, behind-the-scenes, cultural impact). It serves as the guide for tagging and assembly of the raw information boundaries within each module.
The content frameworks define what populates the system’s structure—an inventory of modules, content types, and editorial/personalization rules—so pages surface the right material at the right time. They specify how recommendations, spotlights, timelines, and feature packages are composed and personalized from user signals (saved items, search history, music-app data), with concrete examples to guide build outs.
page content structure

This outlines page-level compositions and modules for each surface. Discover includes Featured Stories, Spotlights, and “More Like This,” all driven by personalization signals with example use cases; Explore is platform wide, organized “By Genre” and “By Artist,” with defined subsections like Underground/Emerging, Genres in Resurgence, and Era-specific explorations, plus artist patterns for resurgence, pioneers/innovators, evolution, and collaborations. Artist and Genre pages then follow repeatable frameworks (origins/evolution, defining characteristics, key works/impact, development, performances, further exploration) that keep layouts consistent while allowing rich and diverse media.
2
The Process
1. Exploring the gap
I began validating my idea by first examining whether demand for such a platform existed. The answer was evident in the ecosystem itself: the sheer volume, diversity, and cadence of music-adjacent resources – databases, maps, interviews, documentaries, forums, podcasts, etc. – signals sustained interest in context, not just access. I then checked whether current applications already addressed the core idea and logged where deep listeners and superfans actually go when they seek information, documenting friction at each step.
Early on, the strongest signals clustered around depth and legibility: listeners want navigability, cohesion, and personalization, while existing products address only slices of the need (catalogs, maps, editorials, biographies, artist websites, magazines) without stitching them together. This gap defined the opportunity as a structuring problem – codify relationships, make sources explicit, and design a path that can scale – setting the groundwork for the IA, taxonomy, and recommendation rules that were to come.
Understanding superfan demand within the market:
2. Discovering what there is to know
I mapped the ecosystem to understand the raw inputs: structured databases and maps (e.g., genre genealogies, artist/track metadata), reference utilities (sampling, credits), and long-form cultural coverage (magazines, NPR/Billboard/Rolling Stone features, documentaries, performance archives). I organized findings by medium – Text, Visual, Video, Audio – to see how context is currently packaged and where provenance and update cadence differ. The output wasn’t “more sources,” but a clear inventory of what exists, how reliable it is, and how each medium would need to be standardized before assembly.
Understanding superfan potential within the market:
3. Recognizing what wants to be known
From that inventory, I distilled the demand signal into six consistent asks: authentic behind-the-scenes stories; deeper creative context and inspiration; cohesive, curated structures (timelines, genealogies, discographies); exclusivity and interactivity; personalization that reflects individual taste and fuels relevant discovery; and the broader culture and community around scenes. This shifted the brief from “collect information” to “surface meaning,” and reframed personalization as something explainable. It also clarified the strategy inflection: leverage existing public media at scale (streaming APIs + a Pinterest-style collections model) rather than rebuild monolithic in-house summaries, and design for gaps where underground/less-documented artists need different treatment.
From cultural phenomena – like Beatlemania and Swifties – to meticulous indexes – such as Every Noise at Once, AllMusic, Discogs – fandom keeps inventing new paths to the music, chasing context as much as sound.
4. Iterating on categorization and IA
Having solidified my direction at this point, I then moved to formalize the content breakdown for both Genres and Artists in order to standardize the framework from the bottom on up while preserving nuance across cases – history/origins, defining characteristics and techniques, notable works, aesthetics/brand cues, behind-the-scenes material, performances, cultural influences, etc. To stress-test my schemas, I focused application on the Shoegaze genre and a related artist – Slowdive. This exposed missing fields, cross-link opportunities (influences, collaborators, scenes), and edge cases, which I resolved before locking hierarchy, tags, and decision pathways. The outcome is a schema that scales while accommodating gaps: standardize what can be standardized, and design graceful fallbacks where sources are thin.

Rough wireframes I created to visualize the preliminary architecture and use cases of the various pages.
5. Identifying how to display it
With structure set, I translated it into page-level compositions: Discover for personalized stories, spotlights, and “More Like This”; Explore as a platform-wide, non-personalized index organized by Genre and Artist with defined subsections (e.g., underground/emerging, resurgence, era lenses); and Home as the user’s saved items, follows, and stats. Initial wireframes clarified module behavior and signposting (labels, tags, smart filters), and the final wireframes tightened density, sequencing, and save interactions. The finalized IA anchors navigation and cross-links so personalization feels legible, not opaque, and each surface stays coherent as the archive scales.
Luminate finds superfans are ~59% more likely than average listeners to want a more personal connection with artists
In a 2023 Goldman Sachs report, Superfan monetization opportunity was estimated at ~$4.2B